线性回归概念
线性回归模型
对于线性回归,首先观察一个简化的模型例子(买房):
- 假设1:影响房价关键因素为卧室个数、卫生间个数、居住面积,记为x1,x2,x3
- 假设2:成交价是关键因素加权和:y=w1x1+w2x2+w3x3+b,其中的权重wi与偏差b的具体值后续再确定
进行抽象提炼后的线性模型概念如下:
- 给定一个n维输入x=[x1,x2,…,xn]⊤
- 线性模型有一个n维权重参数w=[w1,w2,…,wn]⊤和一个标量偏差b
- 最终的输出是输入的加权和:y=w1x1+w2x2+⋯+wnxn+b=<w,x>+b
线性模型也可以被视作单层神经网络。
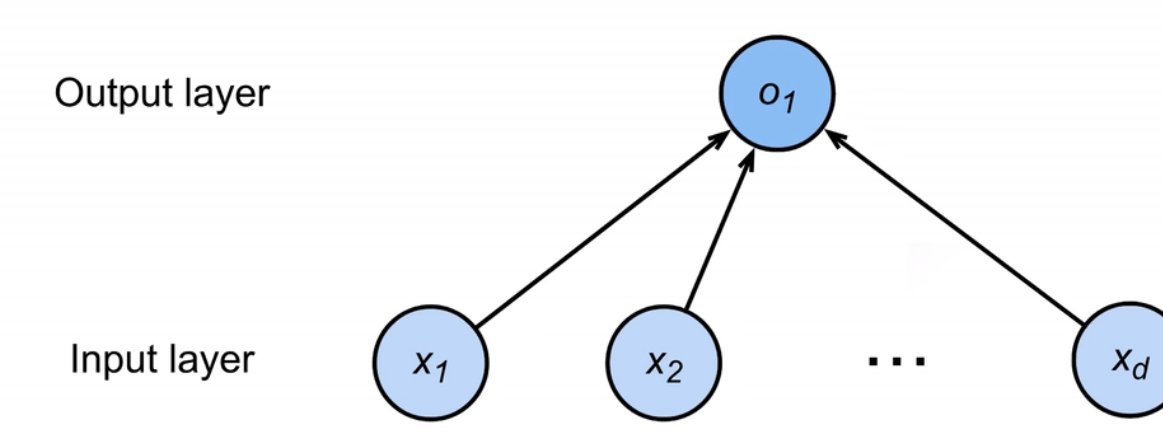
有了这样一个线性模型,就可以对输入进行预估,在预估后,也可以衡量预估质量:也就是说,需要比较真实值和预估值,来衡量目前的模型导致的预估偏差。
举例:设y是真实值,y^是估计值,则可以比较ℓ(y,y^)=21(y−y^)2,求得的偏差估计被称作平方损失。
在拥有了模型及损失函数后,就可以收集数据点对模型进行训练,以确定参数值。这些数据被称为训练数据,通常越多越好。假设有n个样本,可以被记为:
X=[x1,x2,…,xn]⊤ (输入数据点)Y=[y1,y2,…,yn]⊤ (输出数据点)
根据数据集和损失函数的表示,可以符号化当前具体的训练损失(单点损失函数均值):
ℓ(X,y,w,b)=2n1i=1∑n(yi−<xi,w>−b)2=2n1∥y−Xw−b∥2
所以最终的目标就是找到一组权重w和偏差b,使上式的损失函数值最小,即通过最小化损失来学习参数:
w∗,b∗=argw,bminℓ(X,y,w,b)
此过程可以求出显式解。求解过程如下:
- 将偏差加入权重(不需要在权重和输入数据点积后再加偏差项),即将输入数据矩阵和权重向量改为:
X←[X,1] , w←[wb]
ℓ(X,y,w)=2n1∥y−Xw∥2
- 将此损失函数标量值对权重变量w求偏导(具体计算方法见[[矩阵计算]]):
∂w∂ℓ(X,y,w)=n1(y−Xw)⊤∂w∂(y−Xw)⊤=n1(y−Xw)⊤X
- 由于损失函数是一个突函数,因此最优解满足偏导数为0的条件(这是唯一有最优解的模型):
∂w∂ℓ(X,y,w)=0⇔n1(y−Xw)⊤X=0⇔(y⊤−w⊤X⊤)X=0⇔w⊤X⊤X=y⊤X⇔w⊤=y⊤X(X⊤X)−1⇔w=(X⊤X)−1X⊤y=w∗
对于线性回归的总结:
- 线性回归是对n维输入的加权再加偏差的结果
- 使用平方损失来衡量预测值和真实值的差异
- 线性回归模型拥有显式最优解(唯一)
- 线性回归模型可以被看作单层神经网络
基础优化方法
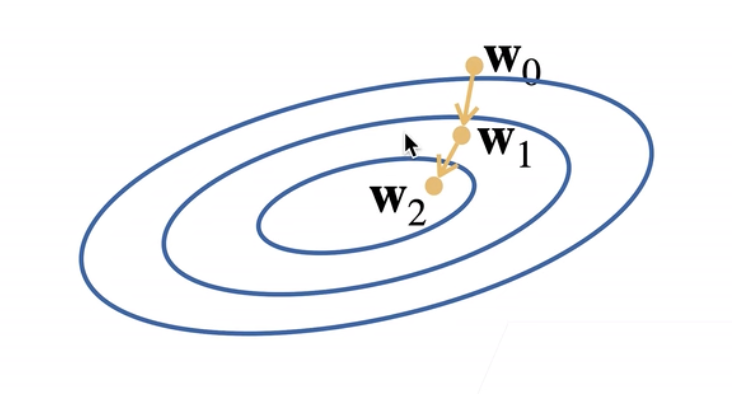
最基础的优化方法为梯度下降法,其工作过程大致为:
- 挑选一个训练参数的随机初始值w0
- 重复迭代参数t=1,2,3…次,每次修正参数值为:
wt=wt−1−η∂wt−1∂ℓ
此方法可以被直观地理解为,每次修正参数,都挑选当前参数所在位置的负梯度方向进行移动(这样可以使损失函数值减小速度最大),而移动的步长参数由(η学习率)给出。图示如下:
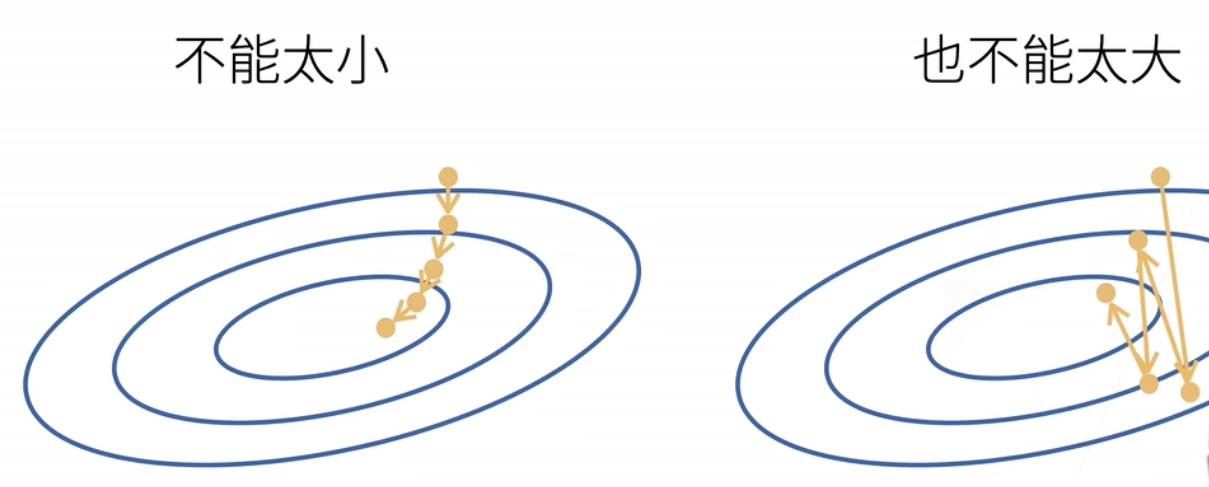
由于η学习率超参数是人为设定的,因此需要进行合适的选择:不能让训练参数变化步长过小(每次参数修正幅度过小,训练轮次过长,算力消耗过大)或过大(可能会导致损失函数值持续的震荡而非稳定下降)。图示如下:
然而这种梯度下降如果在整个训练集上计算会导致算力消耗过大,因为损失函数梯度下降的算力需求和训练集大小(数据个数)线性相关。因此可以采取小批量随机梯度下降的方式。
即,可以对训练集随机采样b个样本i1,i2,…,ib,并只使用这些样本值投入损失函数来近似损失。即此时的损失函数已经缩小变为:
b1i∈Ib∑ℓ(xi,yi,w)
此处b代表选择样本的批量大小,是另一个人为决定的重要超参数。当批量大小过小时,每次计算量过少,不适合并行以最大利用计算资源;当批量大小过大时,会导致内存消耗增加,且如果出现类似相同样本同时被选取会导致计算资源被浪费。
总结如下:
- 梯度下降通过不断沿反梯度方向更新参数求解
- 小批量随机梯度下降是深度学习默认的求解算法
- 两个重要的超参数是批量大小和学习率
后续线性回归的Pytorch实现见[[线性回归实现]]。
线性回归实现
线性回归基本实现
- 首先进行一些包的导入,需要
random是因为随机梯度下降与参数初始化都需要随机函数:
1
2
3
| import random
import torch
from d2l import torch as d2l
|
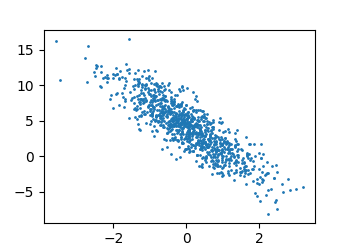
- 然后可以使用一个有噪声的线性模型构造一个人造数据集。此处采用一个权重参数w=[2,−3.4]⊤,偏移参数b=4.2与一个随机噪声项ϵ生成的数据集(输入数据X)与标签(输出数据y)。生成公式为:
y=Xw+b+ϵ
1
2
3
4
5
6
7
8
9
10
| def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
|
- 可以通过各种方式查看生成的数据集情况。输出形式为:
feature中的每一行包含一个二维数据样本,label的每一行包含一个一维标签值。
1
2
3
4
5
6
| print('features:', features[0], ' label:', labels[0])
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)
|
- 接下来需要定义一个
data_iter函数,这个函数接收批量大小、特征矩阵和标签向量作为输入,生成一个大小为批量大小batch_size的小批量数据。其基本原理就是将整个特征矩阵的每一组特征下标取出并打乱,再按照批量大小分割分次取出一组下标,根据这组下标提取一个小批量的特征和标签值。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i:min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
""" 取出的第一个批量组特征矩阵和标签向量情况:
tensor([[ 0.7822, 0.9483],
[-0.7168, -0.2984],
[-0.9692, 1.5418],
[ 1.8321, 0.6736],
[ 0.5797, 1.3481],
[ 0.7215, 0.4682],
[-0.4120, 1.0038],
[-0.6678, -1.8695],
[ 0.0059, -0.5556],
[-1.5461, 0.7406]])
tensor([[ 2.5308],
[ 3.7727],
[-2.9753],
[ 5.5850],
[ 0.7556],
[ 4.0652],
[-0.0372],
[ 9.2070],
[ 6.1038],
[-1.4036]])
"""
|
- 在数据设置完成后,需要对模型参数(w,b)进行定义和初始化,同时也需要对模型进行定义:
1
2
3
4
5
6
7
8
| w = torch.normal(0, 0.1, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
def linreg(X, w, b):
""" 线性回归模型位置 """
return torch.matmul(X, w) + b
|
- 然后需要定义损失函数(使用均方损失)。为了保险起见,可以通过
reshape确保估计值和真知矩阵的形状一致:
1
2
| def squared_loss(y_hat, y):
return (y_hat - y.reshape(y_hat.shape))**2 / 2
|
- 然后需要定义一个优化算法,让参数沿着梯度反方向移动以进行优化。具体的理论知识参见[[线性回归]]。代码如下:
1
2
3
4
5
| def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
|
- 定义训练过程。可以根据输出发现经过训练,预测值与真实值的差距(通过损失值体现)不断下降:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y)
l.sum().backward()
sgd([w, b], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
""" 输出:
epoch 1, loss 0.055857
epoch 2, loss 0.000265
epoch 3, loss 0.000052
"""
|
- 可以通过比较真实设置的参数和训练学到的参数来评估训练的成功程度,相关代码如下:
1
2
3
4
| print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
|
线性回归简洁实现
- 所谓简洁实现,就是使用深度学习框架来进行实现一个线性回归模型(利用了
torch.utils中的data来进行一定的数据操作),首先进行包的引入和数据生成:
1
2
3
4
5
6
7
8
| import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
|
- 对于数据处理,现在可以使用一个PyTorch中的数据迭代器
TensorDataset进行处理。只需要将输入的特征矩阵X和标签b构合并成一个矩阵([X∣b])就可以转化为此数据迭代器对象。同时,此数据迭代器还可以使用DataLoader方法随机取出batch_size个数据点,以便后续训练:
1
2
3
4
5
6
7
8
9
| def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
print(next(iter(data_iter)))
|
- 对于线性回归模型,可以直接使用PyTorch定义好的层(
nn即神经网络的缩写),此处使用的是线性回归,因此只需要使用Linear并指定输入输出对象维度即可。此处将设定好的层放入了一个层容器Sequential中进行保存(以后访问这一层的模型只需要通过net[0]即可):
1
2
3
| from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
|
- 使用
nn.Linear()时需要定义初始化模型参数。定义的内容包括权重weight和偏差bias。初始化方法如下:
1
2
| net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
|
- 均方误差是常用的误差,可以直接使用
MSELoss类计算(也称为平方L2范数):
- 同时使用sgd优化算法进行参数的优化也是常见的。此处只需要通过实例化
SGD实例即可实现:
1
| trainer = torch.optim.SGD(net.parameters(), lr=0.03)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
""" 输出:
epoch 1, loss 0.000227
epoch 2, loss 0.000098
epoch 3, loss 0.000098
"""
|