Softmax回归
Softmax
Softmax回归与线性回归针对的问题不同:线性回归解决的是回归问题、目标是针对输入估计一个连续值(例如根据房子的各个属性预测房价);而Softmax回归解决的是分类问题、目标是针对输入对象预测一个离散类别(例如根据手写的数字图像分类其属于0~9哪个数字,这就是一个10类分类问题)。
回归与分类的差别如下:
回归:单连续数值输出,输出区间为自然区间R R R
分类:通常有多个输出,输出i i i i i i
如果要解决分类问题,需要以下建模:
对类别进行一位有效编码(y i y_i y i i i i
y = [ y 1 , y 2 , … , y n ] ⊤ y i = { 1 , i f i = y 0 , o t h e r w i s e \begin{split}
& \textbf{y} = \begin{bmatrix}y_1, y_2, \dots, y_n \end{bmatrix} ^\top \\
& y_i = \begin{cases}1 \space , \space if \space i = y \\
0 \space , \space otherwise\end{cases}
\end{split}
y = [ y 1 , y 2 , … , y n ] ⊤ y i = { 1 , i f i = y 0 , o t h er w i se
使用均方损失训练
最大值作为模型预测:y ^ = arg max i o i \hat{y} = \arg\max_io_i y ^ = arg max i o i o i oi o i i i i
最终的目标是需要更置信的识别正确类(正确类的置信度以一个阈值远高于其他类置信度),即:o y − o i ≥ Δ ( y , i ) o_y - o_i \geq \Delta(y, i) o y − o i ≥ Δ ( y , i )
使用softmax使输出匹配概率。即输出值y i ^ \hat{y_i} y i ^ o i o_i o i
y ^ = s o f t m a x ( o ) y i ^ = e x p ( o i ) ∑ k e x p ( o k ) \begin{split}
& \hat{\textbf{y}} = softmax(\textbf{o}) \\
& \hat{y_i} = \frac {exp(o_i)}{\sum_{k}exp(o_k)}
\end{split}
y ^ = so f t ma x ( o ) y i ^ = ∑ k e x p ( o k ) e x p ( o i )
利用概率y \textbf{y} y y ^ \hat{\textbf{y}} y ^
衡量真实概率和预测概率的区别需要使用交叉熵。交叉熵常用来衡量两个概率的区别,公式为:
H ( p , q ) = ∑ i − p i log ( q i ) H(\textbf{p}, \textbf{q}) = \sum_i -p_i\log(q_i)
H ( p , q ) = i ∑ − p i log ( q i )
如果使用交叉熵作为真实概率和预测概率间的损失函数,则公式推导如下。注意,由于真实概率向量y \textbf{y} y y y y
l ( y , y ^ ) = − ∑ i y i log y i ^ = − log y y ^ l(\textbf{y}, \hat{\textbf{y}}) = - \sum_i y_i \log \hat{y_i} = - \log \hat{y_y}
l ( y , y ^ ) = − i ∑ y i log y i ^ = − log y y ^
而对这个损失函数求o i o_i o i
∂ o i l ( y , y ^ ) = s o f t m a x ( o ) i − y i = e x p ( o i ) ∑ k e x p ( o k ) − y i \begin{split}
\partial_{o_i}l(\textbf{y}, \hat{\textbf{y}}) = softmax(\textbf{o})_i - y_i =
\frac {exp(o_i)}{\sum_{k}exp(o_k)} - y_i
\end{split}
∂ o i l ( y , y ^ ) = so f t ma x ( o ) i − y i = ∑ k e x p ( o k ) e x p ( o i ) − y i
总结:
Softmax回归是一个多类分类模型
使用Softmax操作子得到每个类的预测置信度
使用交叉熵来衡量预测和标号的区别
损失函数
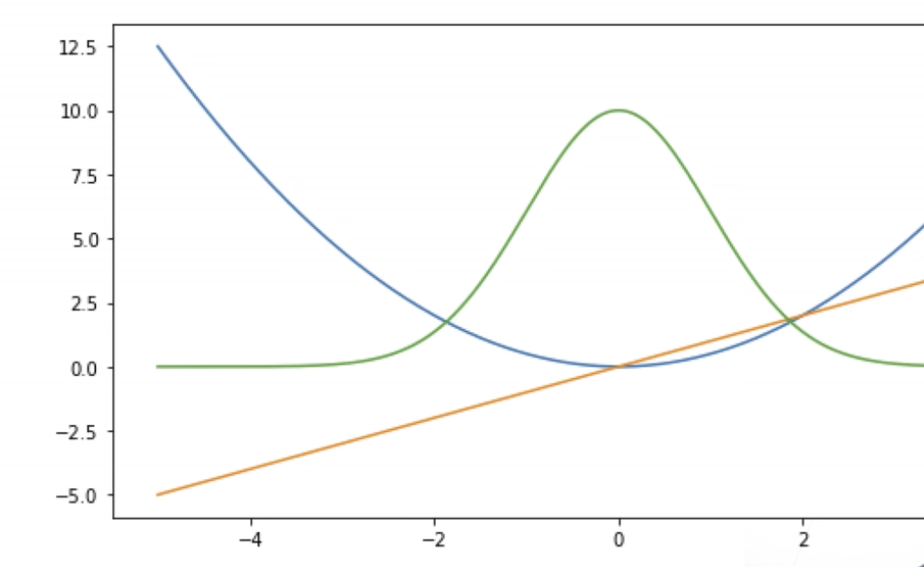
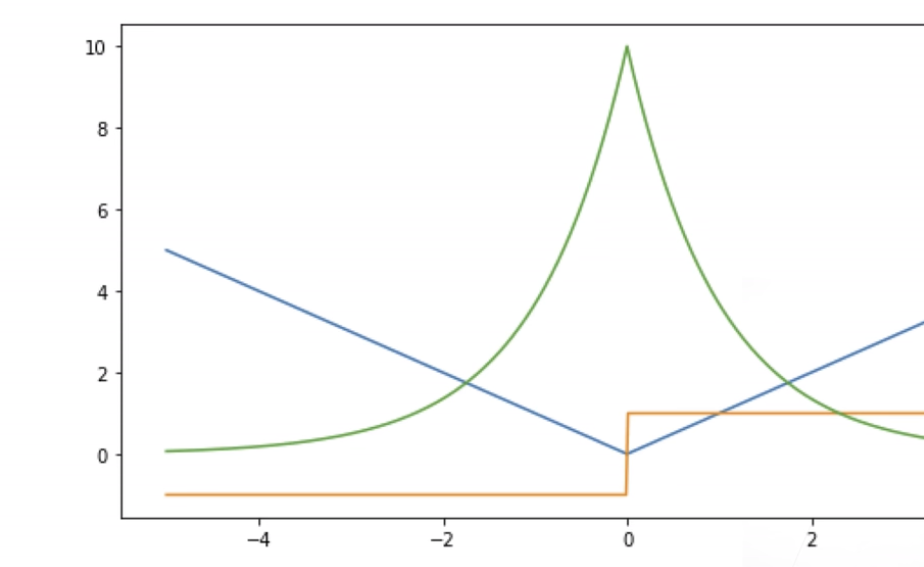
目前已经了解了几种常见的损失函数及图示(蓝色曲线表示真值为0时损失值随预测值的变化、绿线表示似然函数、黄线表示真值为0时梯度大小随预测值的变化):
L2 Loss:l ( y , y ′ ) = 1 2 ( y − y ′ ) 2 l(y, y') = \frac{1}{2}(y - y')^2 l ( y , y ′ ) = 2 1 ( y − y ′ ) 2
L1 Loss:l ( y , y ′ ) = ∣ y − y ′ ∣ l(y, y') = |y - y'| l ( y , y ′ ) = ∣ y − y ′ ∣
Huber’s Robust Loss:l ( y , y ′ ) = { ∣ y − y ′ ∣ − 1 2 , i f ∣ y − y ′ ∣ > 1 1 2 ( y − y ′ ) 2 , o t h e r w i s e l(y, y') = \begin{cases}|y - y'|-\frac{1}{2} \space , \space if \space |y - y'| > 1 \\ \frac{1}{2}(y - y')^2 \space , \space otherwise \end{cases} l ( y , y ′ ) = { ∣ y − y ′ ∣ − 2 1 , i f ∣ y − y ′ ∣ > 1 2 1 ( y − y ′ ) 2 , o t h er w i se
这种损失函数结合了以上两种损失函数的优点,在预测值和真实值相隔较远时采用绝对值损失,使梯度绝对值不会过大;在预测值和真实值相隔较近时采用平方损失,使梯度绝对值在靠近零点时不会震荡或不存在,同时梯度绝对值也会下降。
Softmax回归实现
图像分类数据集
MNIST数据集在图像分类中广泛应用,但是作为基准数据集过于简单,后续训练中将会使用类似但是更加复杂的Fasion-MNIST数据集。相关库的引入如下:
1 2 3 4 5 6 7 import torchimport torchvision from torch.utils import data from torchvision import transforms from d2l import torch as d2l
接着需要通过框架中的内置函数下载Fashion-MNIST数据集并读取入内存。具体代码如下:
1 2 3 4 5 6 7 8 trans = transforms.ToTensor()"../data" , train=True , transform=trans, download=True )"../data" , train=False , transform=trans, download=True )print (len (mnist_train), len (mnist_test)) print (mnist_train[0 ][0 ].shape)
在读取时首先要使用transforms.ToTensor进行图像的预处理,此方法指示将图像转化为32位浮点数格式。然后分别下载Fashion-MNIST中的训练集和测试集,并需要规定下载内容的格式为之前指定图像预处理后的tensor格式,而非简单的图片。
下载完成后可以查看数据集的一些信息:该数据集中包含60000张训练集图像、10000张测试集图像;利用mnist_train[0][0]可以定位到第一张图像(第二维[0]代表图像,[1]代表label标号),发现图像大小为长宽28个像素、黑白(第一维阿尔法值长度为1)。
然后设置了一个返回数据集文本标签的可视化函数(针对输入labels中的各个数字标签,找到并输出对应的文字类别标签。例如从0找到t-shirt):
1 2 3 4 5 def get_fashion_mnist_labels (labels ):'t-shirt' , 'trouser' , 'pullover' , 'dress' , 'coat' , 'sandal' ,'shirt' , 'sneaker' , 'bag' , 'ankle boot' ]return [text_labels[int (i)] for i in labels]
还设置了一个用以可视化数据集样本的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def show_images (imgs, num_rows, num_cols, titles=None , scale=1.5 ):for i, (ax, img) in enumerate (zip (axes, imgs)): if torch.is_tensor(img):else :False )False )if titles:return axes
这个函数的作用是批量化展示图像(将图像列表imgs按照num_rows行、num_cols列显示),同时可以添加每一张图的标签、通过scale控制图像的尺寸。
可以使用以上两个方法与之前自动求导实现中提到的DataLoader方法实现对于一个批次数据图像和标签的展示:
1 2 3 4 next (iter (data.DataLoader(mnist_train, batch_size=18 ))) 18 , 28 , 28 ), 2 , 9 , titles = get_fashion_mnist_labels(y))"pic1.png" )
现在就可以模拟训练时的数据读取真实情况。可以在DataLoader创建时指定要用多少个线程进行读取(即num_workers参数),一般会使用几个线程同时进行读取以保证读取速度快于训练速度,不会导致性能瓶颈。测试当前训练集一轮训练所需时间:
1 2 3 4 5 6 7 8 9 10 11 batch_size = 256 def get_dataloader_workers ():return 4 True , num_workers=get_dataloader_workers())for X, y in train_iter:continue print (f'{timer.stop():.2 f} sec' )
最后就可以统合之前的所有内容,实现一个可以后续重用的Fasion-MNIST读取函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def load_data_fashion_mnist (batch_size, resize=None ):if resize: 0 , transforms.Resize(resize))"../data" , train=True , transform=trans, download=True )"../data" , train=False , transform=trans, download=True )return (data.DataLoader(mnist_train, batch_size, shuffle=True ,False ,
Softmax基本实现
首先进行基本的库引入和数据的加载,设置批次读取量为256,并使用上一节中的Fashion-MNIST读取方法批量下载读取数据集:
1 2 3 4 5 6 import torchfrom IPython import displayfrom d2l import torch as d2l256
然后需要设置权重和偏移的初始值。注意:Softmax模型需求的输入是一个一维向量、输出的也是一个长度等于分类量的一维向量。而数据集中的图片为28个像素长宽的单通道图像,因此此处需要将图像像素信息拉伸拼接为一个28 * 28 = 784长度向量作为输入。
同时,我认为可以理解为这个输入的向量需要针对每一个分类输出都给出自己的权重,因此其实权重是一个输入元素数 * 输出分类数的矩阵、偏移也是一个长度为输出分类数的一维向量(我暂时理解为多个线性回归的拼接)。代码如下:
1 2 3 4 5 num_inputs = 784 10 0 , 0.01 , size=(num_inputs, num_outputs), requires_grad=True )True )
根据Softmax回归中所讲,对于一个向量的Softmax操作如下:
y ^ = s o f t m a x ( o ) y i ^ = e x p ( o i ) ∑ k e x p ( o k ) \begin{split}
& \hat{\textbf{y}} = softmax(\textbf{o}) \\
& \hat{y_i} = \frac {exp(o_i)}{\sum_{k}exp(o_k)}
\end{split}
y ^ = so f t ma x ( o ) y i ^ = ∑ k e x p ( o k ) e x p ( o i )
那么此时,对于一个矩阵来说,其Softmax等同于对每一行的行向量进行Softmax操作再整合(还是需要注意Softmax操作的目的:将参数转化为和为1的非负概率):
s o f t m a x ( X ) i j = e x p ( X i j ) ∑ k e x p ( X i k ) softmax(\textbf{X})_{ij} = \frac {exp(\textbf{X}_{ij})}{\sum_{k}exp(\textbf{X}_{ik})}
so f t ma x ( X ) ij = ∑ k e x p ( X ik ) e x p ( X ij )
在代码中定义一个矩阵的Softmax操作如下:
1 2 3 4 def softmax (X ):sum (1 , keepdim=True ) return X_exp / partition
然后就可以定义求结果的网络方法了。注意:需要将输入内容转化为一个批次大小 * 照片转化一维向量长度的矩阵,才能进行计算,即和权重矩阵进行矩阵乘法后再和偏移分别相加:
1 2 def net (X ):return softmax(torch.matmul(X.reshape((-1 , W.shape[0 ])), W) + b)
然后需要实现交叉熵损失函数。交叉熵损失函数的数学公式如下:
l ( y , y ^ ) = − ∑ i y i log y i ^ = − log y y ^ l(\textbf{y}, \hat{\textbf{y}}) = - \sum_i y_i \log \hat{y_i} = - \log \hat{y_y}
l ( y , y ^ ) = − i ∑ y i log y i ^ = − log y y ^
所以代码编写如下:
1 2 def cross_entropy (y_hat, y ):return -torch.log(y_hat[range (len (y_hat)), y])
根据公式可知,每一组数据的所有预测值最终只需要真实值类别对应的预测值进行求对数再取反即可,因此对于每一组数据,只需要获得其真实值对应的类别预测值即可,这也正是y_hat[range(len(y_hat)), y]的意义:为每一组取出其真实类别的预测值。
然后进行正确率的计算,即统计当前批次中有多少组的预测正确(预测正确数除以每组数据量即为该组预测正确率)。代码如下:
1 2 3 4 5 def accuracy (y_hat, y ):if len (y_hat.shape) > 1 and y_hat.shape[1 ] > 1 : 1 ) type (y.dtype) == y return float (cmp.type (y.dtype).sum ())
然后可以再定义一个函数,用来对指定模型、指定组规模进行正确率的计算。代码如下:
1 2 3 4 5 6 7 def evaluate_accuracy (net, data_iter ):if isinstance (net, torch.nn.Module): eval ()2 )for X, y in data_iter:return metric[0 ] / metric[1 ]
其大致作用是:针对数据集的每一个批次,预测结束后(预测过程可自己设置并通过net参数传入)统计该组预测正确数据数,将预测正确数据数和该组总数据数输入累加器,最后就可以得到整个数据集的预测正确数和总数据数,然后相除就可以得到总正确率。
此处附加代码为累加器代码设置:
1 2 3 4 5 6 7 8 9 class Accumulator :def __init__ (self, n ):self .data = [0.0 ] * ndef add (self, *args ):self .data = [a + float (b) for a, b in zip (self .data, args)]def reset (self ):self .data = [0.0 ] * len (self .data)def __getitem__ (self, idx ):return self .data[idx]
然后是单轮训练方法代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def train_epoch_ch3 (net, train_iter, loss, updater ):if isinstance (net, torch.nn.Module):3 )for X, y in train_iter:if isinstance (updater, torch.optim.Optimizer): float (l) * len (y), accuracy(y_hat, y), y.size().numel())else : sum ().backward()0 ]) float (l.sum ()), accuracy(y_hat, y), y.numel())return metric[0 ] / metric[2 ], metric[1 ] / metric[2 ]
然后是整个训练过程的方法定义,整体思路就是定义整体轮数后在每一轮中调用单轮训练方法。代码如下:
1 2 3 4 5 6 7 def train_ch3 (net, train_iter, test_iter, loss, num_epochs, updater ):for epoch in range (num_epochs):print (f'epoch:{epoch} , test_acc:{test_acc} ' )print (f'finish! train_loss:{train_loss} , train_acc:{train_acc} ' )
对于模型中参数的优化方法,依然适用线性回归实现中定义的sgd方法。学习率与优化方法定义如下:
1 2 3 4 lr = 0.1 def updater (batch_size ):return d2l.sgd([W, b], lr, batch_size)
最后就可以使用train_ch3函数进行整体训练了。训练代码及输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 num_epochs = 10 """ 输出: epoch:0, test_acc:0.7958 epoch:1, test_acc:0.8091 epoch:2, test_acc:0.8116 epoch:3, test_acc:0.8208 epoch:4, test_acc:0.8209 epoch:5, test_acc:0.8073 epoch:6, test_acc:0.8316 epoch:7, test_acc:0.8296 epoch:8, test_acc:0.8292 epoch:9, test_acc:0.8316 finish! train_loss:0.4470104190826416, train_acc:0.8483666666666667 """
还可以对测试数据集的其中一组测试数据进行抽样预测。代码如下:
1 2 3 4 5 6 7 8 9 10 def predict_ch3 (net, test_iter, n=6 ):for X, y in test_iter:break 1 ))for true, pred in zip (trues, preds)]0 :n].reshape((n, 28 , 28 )), 1 , n, titles=titles[0 :n])"pic2.png" )
输出图像如下(标题为模型预测标签):
Softmax回归简洁实现
开始的步骤同基本实现类似,需要引入一定库、设置每次读取数据的批量大小、读取Fashion-Minst数据集中的训练和测试集:
1 2 3 4 5 6 import torchfrom torch import nnfrom d2l import torch as d2l256
此时模型就可以通过nn进行构建,注意,由于Pytorch无法隐式的将一个多维的矩阵展平(正如前文所说Softmax需要一个一维向量输入),因此需要调用一个Flatten()层,此层可以讲输入第零维不变(代表不同数据点),其他维展平变成一个维度。同时还需要初始化权值:当检测到当前初始化的是Softmax的线性层时,就进行权值的均值0方差0.01的初始化。代码如下:
1 2 3 4 5 6 7 net = nn.Sequential(nn.Flatten(), nn.Linear(784 , 10 ))def init_weights (m ):if type (m) == nn.Linear:0.01 )
然后需要设置损失函数与优化算法。损失函数依然为交叉熵损失,可以直接使用nn.CrossEntropyLoss这一内置算法;优化算法使用torch.optim.SGD,对net网络中所有的参数进行学习率为0.1的优化:
1 2 loss = nn.CrossEntropyLoss0.1 )
最后直接将这些设定好的内容输入上一节的train_ch3进行训练即可。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 num_epochs = 10 """ 输出: epoch:0, test_acc:0.7948 epoch:1, test_acc:0.8 epoch:2, test_acc:0.8202 epoch:3, test_acc:0.8166 epoch:4, test_acc:0.8265 epoch:5, test_acc:0.8313 epoch:6, test_acc:0.8317 epoch:7, test_acc:0.8276 epoch:8, test_acc:0.824 epoch:9, test_acc:0.8324 finish! train_loss:0.44748177267710365, train_acc:0.8476833333333333 """